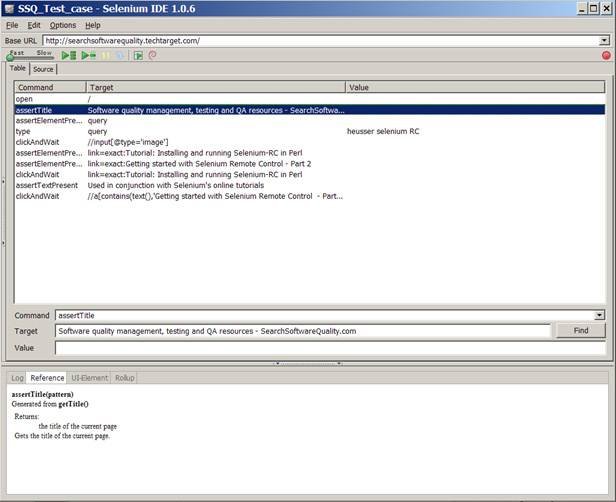
Java 7 (codename Dolphin) is a major update to Java that was launched on July 7, 2011.
The Java 7 release initially included many JSRs
with exciting features, like support for closures, which were later
deferred to Java 8 in order to release JSRs that are already done.
Java Releases
Here’s a quick snapshot of the past
Java release dates (table 1). There are several small new features
and enhancements in Java 7. Out of the 28 features that I looked
at, here are the ones that I found useful.

New features and
enhancements
#1 Strings in
switch
In programming, we often encounter
situations where we need to do different things based on different
values of a variable. For Boolean variables, an if-then-else
statement is the perfect way of branching code. For primitive
variable types we use the switch statement. However, for String
variables, we tend to resort to using multiple if-then-else
branches as follows.
Java 6 and
Before

One workaround for this is to
convert the String into an enum and then switch on the enum.
Java 7
Java 7, however, has added a
language level support for String in switch. Now you can rewrite
the same code more elegantly:

Not only does this help us write
more readable code, but it also helps the compiler generate more
efficient byte code as compared to the if-then-else by actually
switching on the hashcode() and then doing an equals() comparison.
Please note that you will get a NullPointerException if the
variable language in the above example resolves to null. I like
this feature, but unlike some of the other enhancements in the past
(like Generic in Java 5), I don’t anticipate using this feature a
lot. Practically, I find myself using if-then-else for one or two
values and resort to an Enum when the number of values are
higher.
#2 try-with-resources
statement
One of the most useful additions in
Java 7 is the auto closing of resources like InputStream which
helps us reduce boiler plate code from our programs. Suppose we
were writing a program which reads a file and closes the
FileInputStream when it’s done, here is how you would write the
program:
With Java 6 and
Before

I want to point out a couple of
things in this code. Firstly, notice that we declare the
FileInputStream outside the try block just so that it can be
accessed in the finally block. The second observation is that we
need to initialize the InputStream to null, so that it is
guaranteed to be initialized when we access it in the finally
block. Last but not the least, the is.close() in the finally block
may throw an Exception as well, thereby hiding the original
Exception thrown in the try block Exception from the caller. What
we probably want is to handle the Exception thrown from is.close()
and throw the original IOException.

The above code still has a
shortcoming that the Exception thrown from finally is supressed and
not accessible to the calling code. I’m not sure how often we want
to get both the original Exception and also the Exception thrown
from the finally block, but if we did want it, we could do always
do something like this:
SuppressedException above is a user
written Java bean with a field named suppressed of type Exception.
The calling code can then call
SupressedException.getThreadLocal().getException() to get the
Exception that was supressed in the finally clause. Great, we
solved all the problems associated with the try-catch-finally! Now
we must remember to repeat this exact sequence with each use of
try-catch-finally when handling files or other resources which need
to be closed. Enter Java 7, and we can do the above without the
boiler plate code.
With Java 7

try can now have multiple statements
in the parenthesis and each statement should create an object which
implements the new java.lang.AutoClosable interface. The
AutoClosable interface consists of just one method.
Each AutoClosable resource created
in the try statement will be automatically closed! If an exception
is thrown in the try block and another Exception is thrown while
closing the resource, the first Exception is the one eventually
thrown to the caller. The second Exception is available to the
caller via the ex.getSupressed() method. Throwable.getSupressed()
is a new method added on Throwable in Java 7 just for this
purpose.
Mandatory catch block when
using the try statement
Note that if you are creating
AutoClosable resources in the try block, you are required to
declare a catch block to catch the concrete exception thrown from
the actual AutoClosable. close() method. Alternatively you need to
throw the Exception. Think of the close() method as implicitly
being called as the last line in the try block. So, if an
application has its own AutoClosable class as follows:

Then, the following will cause a
compile error:

To fix the above, you need to catch
or throw the Exception from the calling method.

Syntax for declaring
multiple resources
The try statement can contain
multiple statements separated by semicolon. Each statement must
result in an AutoClosable object.

It is illegal to declare any
variable which isn’t an AutoClosable.

Output
ERROR: try-with-resources not
applicable to variable type
required: AutoCloseable
found: long
required: AutoCloseable
found: long
AutoClosable vs
Closable
The old Closable interface
introduced in Java 5, which also has the same method that now
extends from AutoClosable, implying that all Closable classes are
automatically Auto-Closable. Those classes automatically become
resources that can be created in the try statement. The slight
difference in AutoClosable and Closable is that unlike
Closable.close(), AutoClosable.close() is not supposed to be
idempotent, which means that calling it twice can have side
effects. The second difference is that since exceptions thrown from
AutoClosable. close() are suppressed, AutoClosable.close() should
not throw exceptions which can cause problems when suppressed, like
the InterruptedException.
#3 More precise
rethrow
There are often situations when we
want to catch multiple exceptions of different types, do
“something” with them, and rethrow them. Let us consider this
example, where we have some code which throws IOException and
SQLException.

In the above example, we are logging
each type of exception being thrown by the try block before
rethrowing them. This results in a duplication of code in the catch
blocks. Before Java 7, to get around the code duplication issue we
would catch the base exception as follows:

However, this requires us to rethrow
the base Exception type java.lang.Exception from the calling
method.
public static void main(String[]
args) throws Exception {
With Java 7
Java 7 has added the “precise
rethrow” feature which lets you catch and throw the base exception
while still throwing the precise exception from the calling
method.
Note the keyword final in the above
catch clause. When a parameter is declared final, the compiler
statically knows to only throw those checked exceptions that were
thrown by the try block and were not caught in any preceding catch
blocks.
#4 Multi-catch
There is no elegant way with Java 6
to catch multiple exceptions of different types and handle them in
the same way.

You can always catch the parent
Exception in order to avoid duplication of code, but it is not
always suitable especially if the parent is java.lang.Exception.
Java 7 lets you catch multiple Exceptions in a single catch block
by defining a “union” of Exceptions to be caught in the catch
clause.

Note that the pipe ‘|’ character is
used as the delimiter. The variable ‘ex’ in the above example is
statically typed to the base class of Ex1 and Ex2, which is
java.lang.Exception in this case.
#5 Binary integral
literals
With Java 7, you can now create
numerical literals using binary notation using the prefix “0b”
int n = 0b100000;
System.out.println("n = " + n);
System.out.println("n = " + n);
Output
n = 32
#6 Underscores in numeric
literals
With Java 7, you can include
underscores in numeric literals to make them more readable. The
underscore is only present in the representation of the literal in
Java code, and will not show up when you print the value.
Without
underscore
int tenMillion = 10000000;
System.out.println(“Amount is “ + tenMillion);
System.out.println(“Amount is “ + tenMillion);
Output
10000000
With underscore
int tenMillionButMoreReadable =
10_000_000;
System.out.println("Amount is " + tenMillionButMoreReadable);
System.out.println("Amount is " + tenMillionButMoreReadable);
Output
10000000
More rules and
examples
1. Consecutive underscores is
legal.
int n = 1000______000;
2. Underscores can be included in
other numeric types as well.
double d = 1000_000.0d;
long l = 1000_000l;
int hex = 0xdead_c0de;
int bytes = 0x1000_0000;
long l = 1000_000l;
int hex = 0xdead_c0de;
int bytes = 0x1000_0000;
3. Underscore can be included after
the decimal point.
double example8 =
1000_000.000_000d;
4. It is illegal to start a literal
with an underscore

5. It is illegal to end a literal
with an underscore.

6. It is also illegal to have
underscore be just before or after a decimal point.

7. Improved type inference
for generic instance creation
Java 5 introduced generics which
enabled developers to write type safe collections. However,
generics can sometimes be too verbose. Consider the following
example where we are creating a Map of List of String.
With Java 5 and
6
Map<String,
List<String>> retVal = new HashMap<String,
List<String>>();
Note that the full type is specified
twice and is therefore redundant. Unfortunately, this was a
limitation of Java 5 and 6.
With Java 7
Java 7 tries to get rid of this
redundancy by introducing a left to right type inference. You can
now rewrite the same statement by using the <> construct.
Map<String,
List<String>> retVal = new HashMap<>();
This does make the code a little
less verbose. You can also use <> construct when returning a
newly created object.

This, in my opinion, goes only half
way. The full solution would have been a right to left full type
inference.
Map map = new HashMap<String,
String>();
The above would have made the code
even less verbose. Though this enhancement can still be done in a
later version.
#8 More new I/O APIs for the
Java platform (NIO.2)
A new set of I/O APIs and features
were introduced in Java 1.4 under the java.nio package. This
addition was called the New I/O APIs, also known as NIO. Naming
something New is always short-sighted because it will not remain
new forever. When the next version comes along, what should the new
version be called, the NEW NEW I/O? Java 1.7 offers a rich set of
new features and I/O capabilities, called NIO.2 (New I/O version
2?). Here are the key highlights of NIO.2.
a) Package
The most important package to look
for is java.nio.file. This package contains many practical file
utilities, new file I/O related classes and interfaces.
b) The java.nio.file.Path
interface
Path is probably the new class that
developers will use most often. The file referred by the path does
not need to exist. The file referred to does not need to exist. For
all practical purposes, you can think of replacing java.io.File
with java. io.Path.
Old Way
File file = new
File("hello.txt");
System.out.println("File exists() == " + file.exists());
System.out.println("File exists() == " + file.exists());
New Way
Path path =
FileSystems.getDefault().getPath("hello.txt");
System.out.println("Path exists() == " + Files.exists(path));
System.out.println("Path exists() == " + Files.exists(path));
c) The java.nio.file.Files
class
The Files class offers over 50
utility methods for File related operations which many developers
would have wanted to be a part of earlier Java releases. Here are
some methods to give you a sense of the range of methods offered. •
copy() – copy a file, with options like REPLACE_EXISTING,
NOFOLLOW_LINKS public static Path copy(Path source, Path target,
CopyOption... options);
• move() – move or
rename a file public static Path move(Path source, Path target,
CopyOption... options);
• newInputStream()
– create input stream public static InputStream newInputStream(Path
path, OpenOption... options);
• readAllBytes() –
similar to the Apache IOUtils.readFile-ToByteArray public static
byte[] readAllBytes(Path path) throws IOException;
•
createSymbolicLink() – creates a symbolic link, if
supported by the file system public static Path
createSymbolicLink(Path link, Path target,
FileAttribute<?>... attrs) throws IOException
d) WatchService
API
WatchService API is a new feature
introduced in Java 1.7. It provides an API that lets you “listen”
to a certain type of file system events. Your code gets called
automatically when those events occur. Examples of event types are
captured by StandardWatchEventKinds class.
• ENTRY_CREATE:an entry is created
or renamed in the directory
• ENTRY_DELETE:an entry is created
or renamed out of the directory
• ENTRY_MODIFY:a directory entry is
modified
Example
Here’s a full example of how to
watch a directory and print any newly created files.

Run the above program. Then create a
file ‘new.txt’ in the directory ‘logs’. The program will print:
logs: new file created new.txt
Video of the event: http://blogs.oracle.com/java/entry/java_7_celebration_begins
Links: